Meta's AI Agent 'KernelEvolve' Slashes Infrastructure Optimization from Weeks to Hours
Breaking: Meta Automates Low-Level AI Performance Tuning with KernelEvolve
MENLO PARK, CA – Meta has unveiled a new autonomous agent, KernelEvolve, that compresses weeks of expert engineering time for optimizing AI hardware kernels into hours of automated search. The system, built to support Meta's Ranking Engineer Agent, has already delivered a 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs and a 25% training throughput gain on Meta’s custom MTIA chips.
“KernelEvolve treats kernel optimization as a search problem,” said Dr. Anna Schmidt, a research scientist at Meta’s AI Infrastructure team. “Our agent evaluates hundreds of candidate kernels per cycle, feeding diagnostic data back to the LLM to iteratively improve performance beyond what human experts achieve.”
The development addresses a critical bottleneck: Meta operates a large fleet of heterogeneous hardware, including NVIDIA and AMD GPUs, its custom MTIA silicon, and CPUs. Each new chip generation and ML model architecture requires hand-authored, chip-specific kernels—a task that no longer scales.
Background: The Kernel Optimization Crisis
High-level AI models must be translated into low-level, chip-specific instructions called kernels. Standard operators like general matrix multiplications (GEMMs) are covered by vendor libraries, but production workloads include many custom operators. With the number of models multiplied by the number of hardware types and generations, hand-tuning by kernel experts is unsustainable.
Meta’s Ranking Engineer Agent (introduced in this series) autonomously designs and executes ML experiments. KernelEvolve extends that capability to the infrastructure layer, generating optimized kernels in high-level DSLs like Triton, Cute DSL, and FlyDSL, as well as low-level languages such as CUDA, HIP, and MTIA C++.
How KernelEvolve Works
KernelEvolve models optimization as a search process: a purpose-built job-harness evaluates each candidate kernel, collects profiling data, and feeds diagnostics back to the LLM. The system then drives a continuous search over hundreds of alternatives, converging on solutions that exceed human-generated kernels.
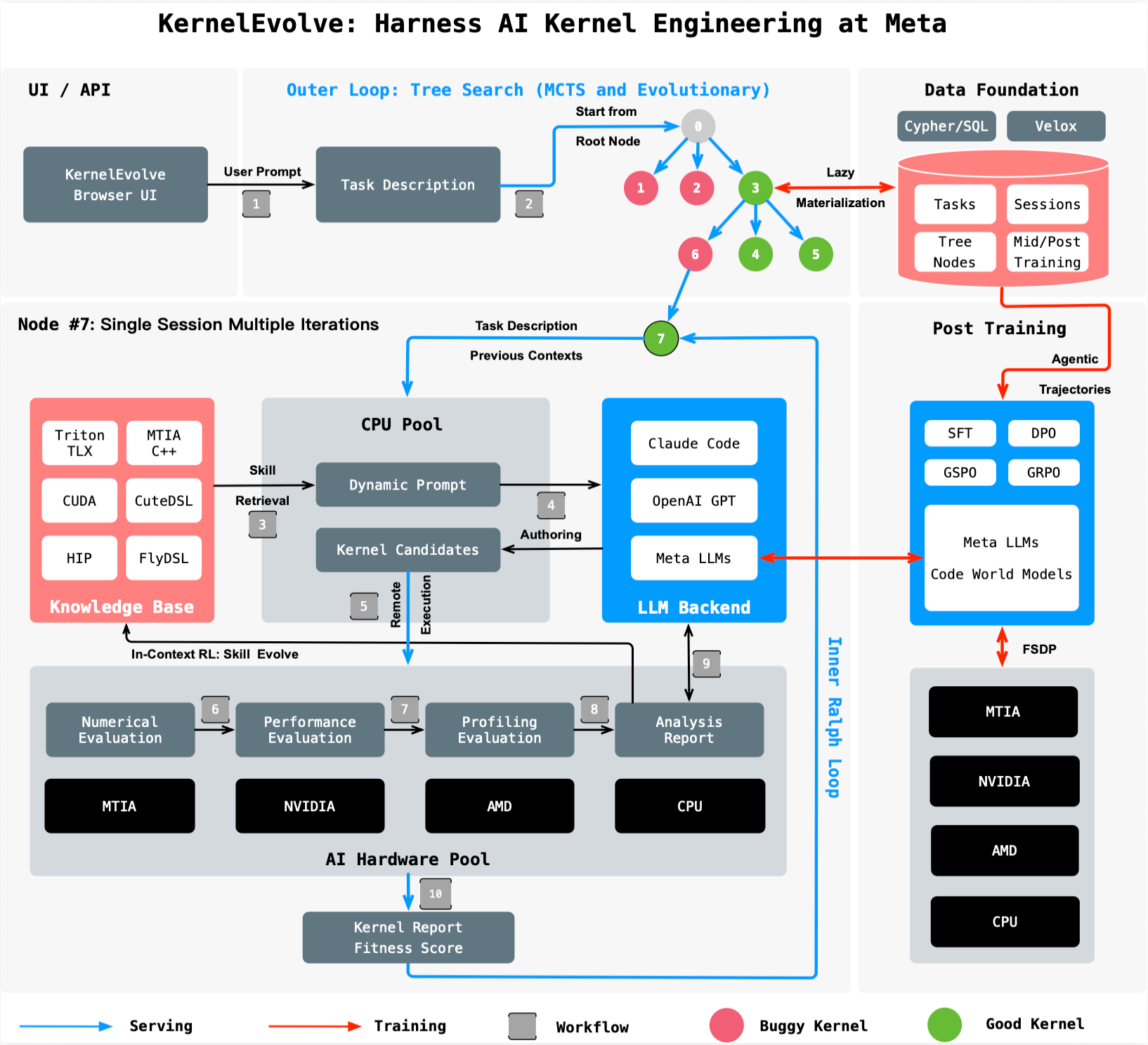
The agent operates across public and proprietary hardware, enabling faster development cycles. “We compressed weeks of profiling, optimizing, and cross-hardware debugging into hours,” said Mark Liu, a software engineer at Meta. “This frees engineers for higher-level design work.”
What This Means for AI Infrastructure
The breakthrough has immediate implications for Meta’s ad ranking and broader AI systems. The 60% inference improvement on NVIDIA hardware directly accelerates ad delivery, while the 25% training boost on MTIA chips speeds up model iteration. KernelEvolve’s broad applicability—spanning GPUs, custom silicon, and CPUs—positions it as a cornerstone for future AI infrastructure.
Additionally, the agent is not limited to ads. Researchers say it can optimize kernels for any AI model, including large language models and generative AI assistants. Meta plans to present the full paper, “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta,” at the 53rd International Symposium on Computer Architecture (ISCA) 2026.
Key Achievements at a Glance
- 60% inference throughput improvement for Andromeda Ads model on NVIDIA GPUs
- 25% training throughput improvement for ads model on Meta MTIA chips
- Supports NVIDIA, AMD, MTIA, and CPU architectures
- Works with Triton, Cute DSL, FlyDSL, CUDA, HIP, and MTIA C++
- Reduces expert engineering time from weeks to hours
With this advancement, Meta takes a significant step toward self-optimizing AI infrastructure—a trend that other hyperscalers are likely to follow.